
A look inside the weather machine
How we manage 100k requests per day with multiple data providers in real time with autoscaling and fallbacks.
One of the consequences of making an app that's designed to be simple is that it's not always obvious how much work is going on behind the scenes.
So, I thought I'd give you a tour of the systems that keep our little Hello Weather machine whirring along every day, rain or shine.
The hybrid app: simultaneously fast and slow
If you recall our earlier post about being on iOS and Android, Hello Weather is a "hybrid" app — meaning a good portion of the product is actually a website which is responsible for doing the bulk of the work to fetch and display weather forecasts.
This means that the humans can move quickly because we get to use the language we know best (Ruby) and release improvements without the overhead of the App Store. To put this in context, I just deployed v1829 (!) of the app this morning and 3 minutes later the change was live for all customers. There's no way we could move this quickly or release improvements this often if we needed to do a native release for every change, not to mention the cross-platform advantages (one change in Ruby is shared between iOS and Android).
However, this also means that the computers might move slowly because all requests route through a single point of failure. If one of our data sources is having a rough day, this can impact the speed of the entire system and slow things down for everyone. To combat this, we've created a fault-tolerant autoscaling system that keeps things humming along without human intervention... but I'm getting ahead of myself just a little bit.
Pay no attention to the app behind the curtain
When you use Hello Weather, the app sends your location (latitude & longitude) to a Ruby on Rails app we host on Heroku, along with a set of options (Celsius or Fahrenheit?) so we know what to display for you.
Of course, this technology choice should come as no surprise, given that we all work (or have worked, I'm a freelancer now 😉) at the home of Ruby on Rails, Basecamp, and so we have a lot of experience with Rails and know how to build things using it.
On the other hand, you may be thinking that Ruby/Rails seems like a less-than-optimal choice for this type of app. To this, I reply: "meh" — we've been able to scale up Hello Weather to handle ~100 requests per minute for less than $100 month in server costs, including large bursts of additional capacity when needed.
Autoscaling
Today we're running Puma on a minimum of 3 dynos each with a minimum of 40 threads each — meaning we can handle 100+ requests simultaneously.
We monitor our throughput and memory use on the Heroku Dashboard, New Relic, and Datadog and we can see strain on the systems there as well.
In our case, the bulk of the time spent serving a request is time spent waiting for a network response from one of our data providers. However, unlike most other apps that try to move external network requests "out of band" into background jobs etc., we need to wait for external network requests to complete since we want to fetch the latest weather data for you every time you use the app.
So, we use a wonderful service called HireFire to automatically increase our capacity when incoming requests start to pile up because one of the sources is running slowly. We like HireFire because they have a set price no matter what your maximum dyno count is, whereas most of their competitors charge substantially more based on that cap.
HireFire also worked with us to develop a new feature on their service which allows scaling based on the request queue time, which is important for us since the time it takes for an external data request isn't in our control and varies quite a bit. In our case, the metric we care about is request queue time which is the difference between the time that the request was accepted into the Heroku Router and the time that our application actually starts processing the request.
If requests are piling up as they're coming in, that means we need to scale up in order to keep things snappy. If responses are being returned a bit more slowly than usual but it's not causing a bottleneck, scaling up would a waste of money.
Fallbacks
We also developed a fallback system that allows us to gracefully handle partial (or complete!) outages of any data source. We use Dark Sky as the fallback for all sources except for Dark Sky itself, in which case we use AccuWeather.
Here's a funny picture of me from a few years ago, before I realized that we might need a fallback system. I was on vacation in a small town in Tuscany drinking wine with friends when Dark Sky went down...

The initial development of the "fallback" system
Fallbacks are caused by two things: timeouts and data errors.
For timeouts, we generally give our data sources 2 seconds to respond to requests. Over the years we noticed that timeouts would spike at the top of every hour (presumably caused by a rush of hourly cron jobs) so we allow 4 seconds at the top of each hour. We also found that we were able to significantly reduce the number of double-timeout errors by allowing 4 seconds if we're already in a fallback scenario.
For data errors, we inspect the responses from our data providers and trigger a fallback if we get anything other than a 200 response code and a valid JSON body in the format expected. (We'll review this in more detail below....)
Autoscaling and fallbacks in action
We recently had a few days where some of our data sources were intermittently slow and/or completely down for extended periods of time. The autoscaling/fallback system handled things without manual intervention, but I did grab a few screenshots to illustrate how the system works in practice when under pressure.
Heroku
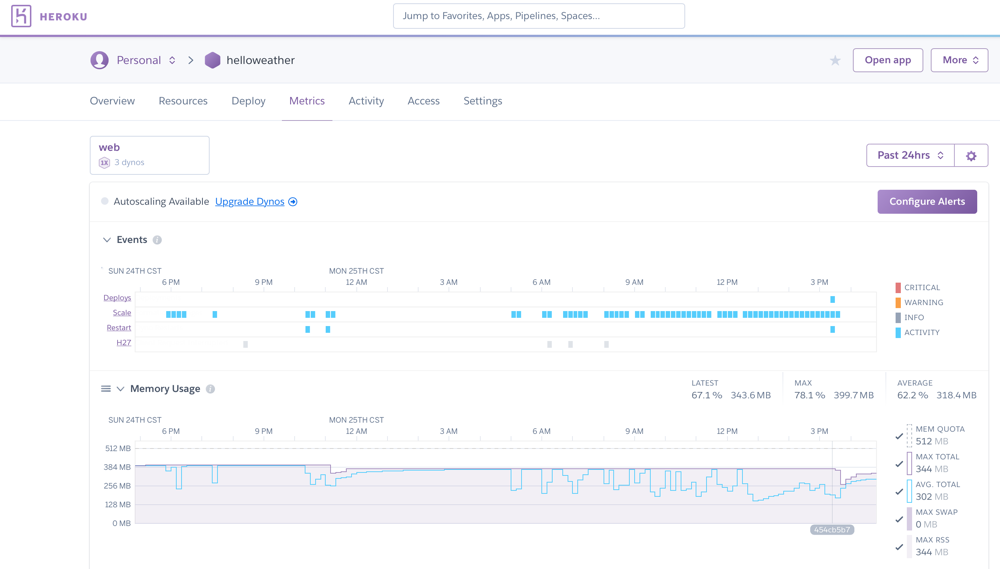

These are two views of the Heroku dashboard — a "bad" day on the left, and a more typical day on the right. On the left, note the row of blue dots, which represent Scale events where HireFire was automatically scaling up in response to an increase in request queue times.
HireFire
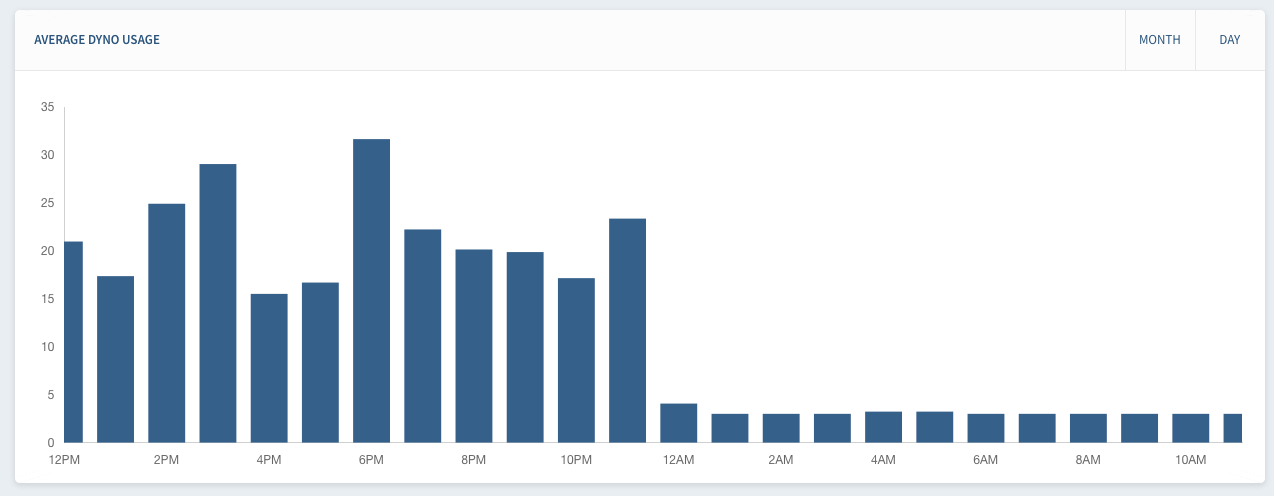
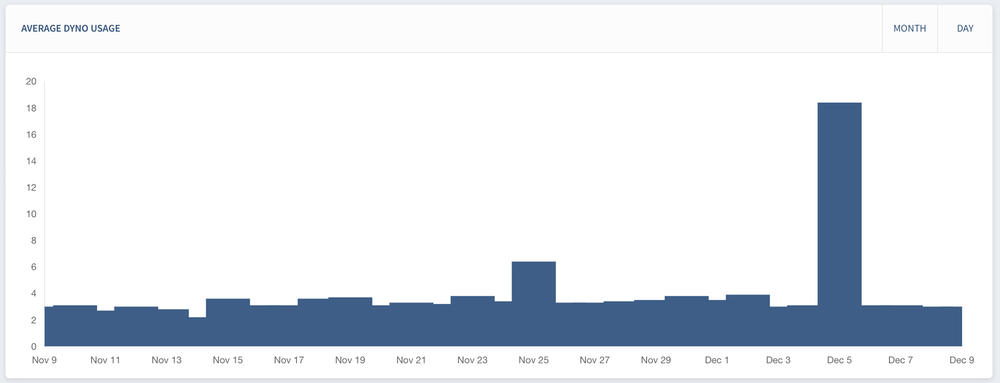
These are two views of the HireFire dashboard. On the left we have an hourly graph where you can see our systems scaling up and then back down over the course of a few hours. On the right we have a daily graph where you can see that Nov 25 and Dec 5 required sustained increases in dynos to handle slowdowns at the data sources. Dec 5 was our worst day on record, requiring an average of 18 dynos — 6x our baseline.
Datadog
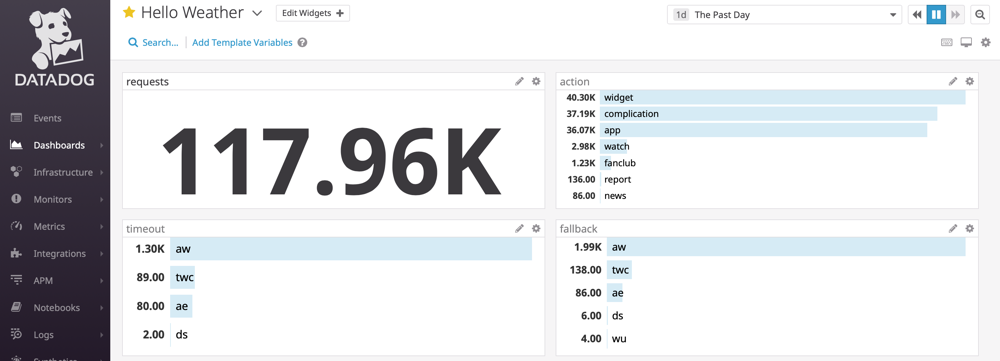

These are two partial views of our custom Datadog dashboard. On the left you'll see a "bad" day when AccuWeather had 1.3k timeouts and a total of nearly 2k fallbacks. On the right, you'll see a more typical (but still worse than usual) day with ~100 fallbacks for ~100k requests served.
As an aside, here's a one-hour view of our full Datadog dashboard where you can see our overall stats. For each incoming request, we send a set of "tags" to Datadog so we can build a few simple graphs. These stats don't include any user-identifiable data, they just give us a rough count of the overall request volume so we can see how many free vs paid users we have, etc.
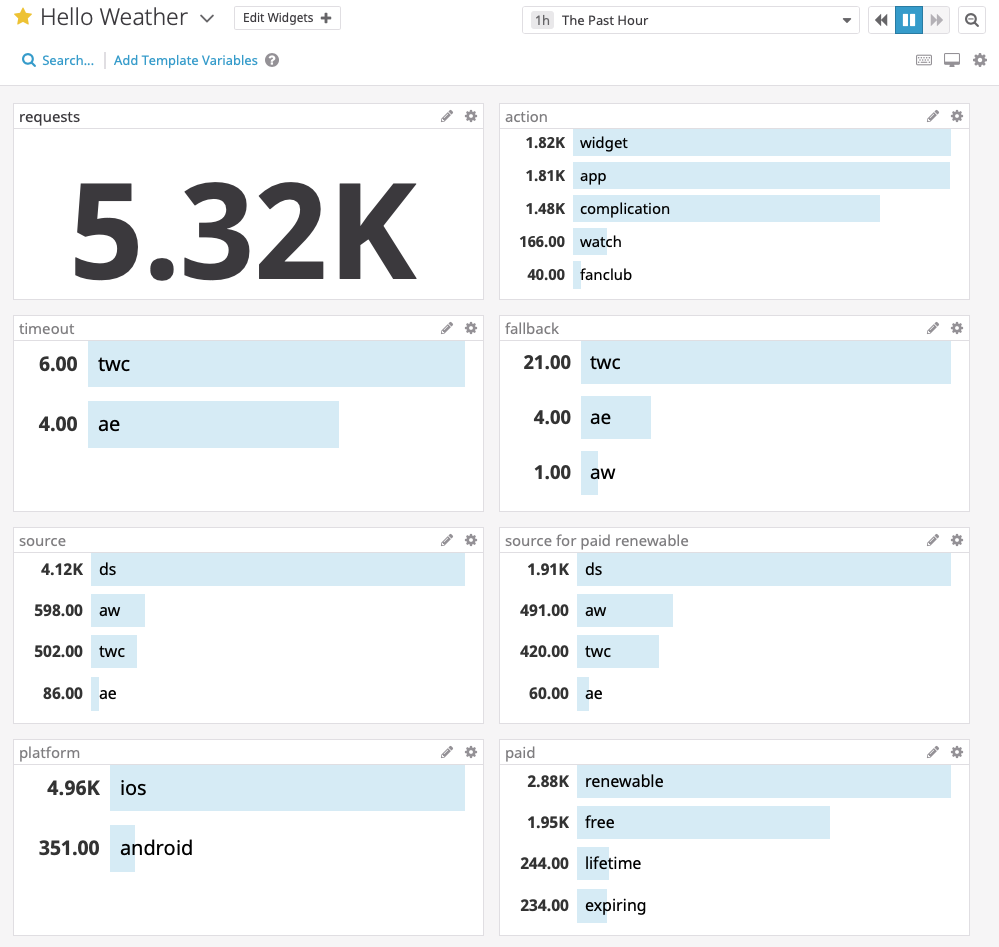
This is a good example of our commitment to user privacy as discussed in a previous blog post. Here, we opted to use a private system that we pay for and control instead of a dubious 3rd party analytics tool that would give us more comprehensive statistics about our users at unknown cost.
NewRelic

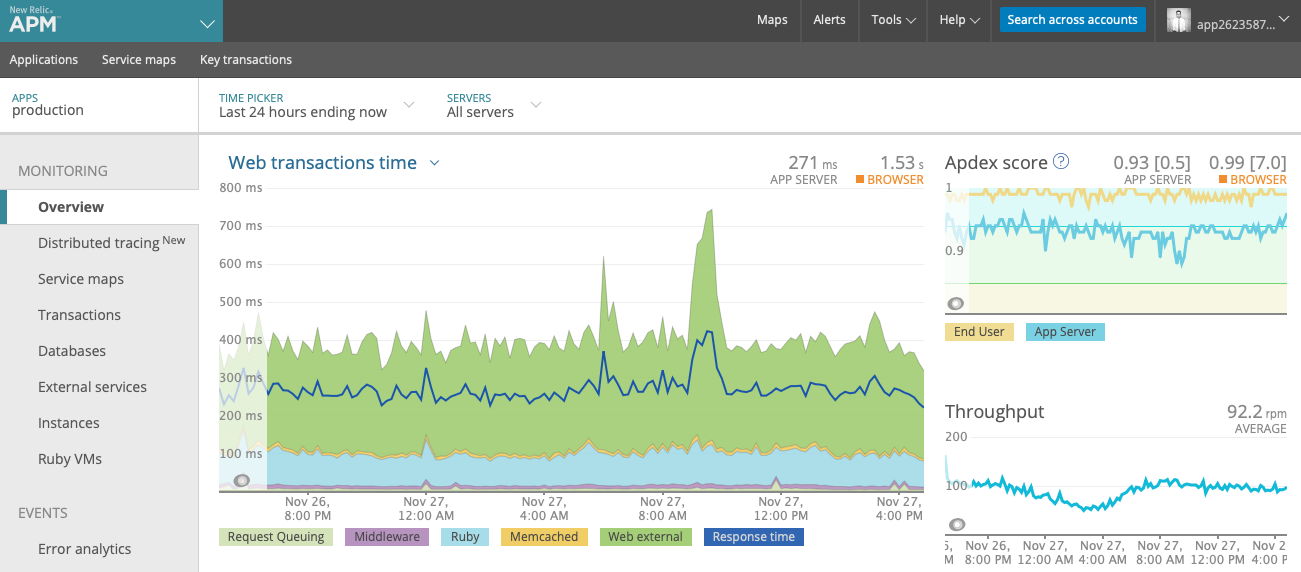
These are two views of our NewRelic dashboard. On the left we isolated the request queuing metrics, so you can see our autoscaling in action as it scales up in response to pressure on the system. On the right you can see a wider view with all metrics visible on a more typical day. Note the spike in web external and response time, without a corresponding increase in request queuing — meaning that our autoscaling kicked in to keep response times as quick as possible.
Sentry
Our fallback system handles timeouts and data issues gracefully and we end up returning surprisingly few errors to our users. Even so, we like to track those "silent" errors to make sure that we're not overlooking possible areas of improvement. We can see an example of that in our Sentry account, which is a wonderful service that we use for error tracking in our Rails and iOS apps.
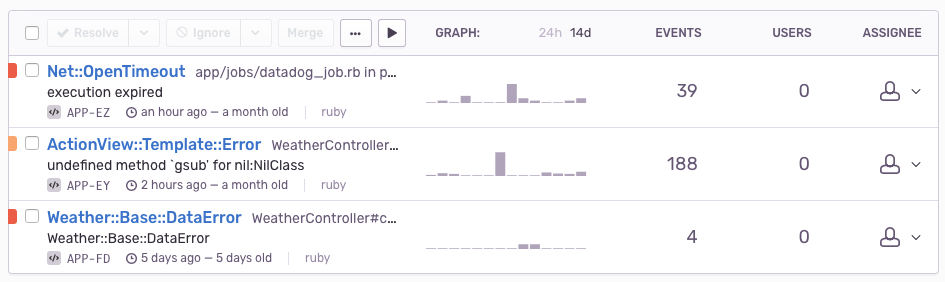
This is a view of errors from the last few days.
The first set of errors are failures encountered while attempting to send stats to Datadog. These stats don't need to be terribly accurate and they don't impact the user, so we're not bothered by a few failures here and there.
The second set of errors has a yellow (orange?) color on the far left. These are "silent" errors that triggered a fallback. We track these in Sentry with the warning level metadata so they're easy to differentiate. Our exception levels are so low (even for these silent errors) that we often notice new data issues before our data providers themselves. By digging into this error, we found that a recent data model change on Dark Sky was causing some daily text summaries to unexpectedly return nil, and we're working with Dark Sky to help identify the cause.
The third set of errors has a red color and a DataError class. The red color indicates (sadly) that we failed (failed!) to deliver a valid response to the user. This only happens if both the original and the fallback source time out or return unusable data. This is quite rare for us — typically we only see one or two per week. DataError is a custom error that we raise after checking the status code and shape of the response. For example, if the data source returns a 500 or an empty array of daily forecasts, we throw a DataError and retry with the fallback source.
Cloudfront and other stuff
While we're talking about the back-end systems that make Hello Weather tick, let's take a quick look at our CloudFront distribution. We use this global CDN to reduce the load on our Heroku dynos by fanning out asset requests, primarily for the weather condition icons.

We also love updown.io for "simple and inexpensive website monitoring" so we get a phone call if the app goes down completely. We use Memcached Cloud for caching, and SendGrid for sending emails submitted through our contact form.
For our data sources, we currently use Dark Sky, AccuWeather, AerisWeather, and The Weather Company. For our radar, we use WeatherOps.
A look at the code
When we first got started, we only supported the Dark Sky data source, so our code was littered with Dark Sky specific data accessors. When we added the now-defunct Weather Underground data source, it took some refactoring to open up the possibility of being "multi-source." Luckily, we'd been using VCR to capture all sorts of weather conditions over the years and had built up quite a large test suite.
To enable moving to an inheritance setup, we had the idea to MD5 the response body for each of our integration tests before making any code changes. This way, we were free to do some aggressive refactoring, while being assured that we weren't making any changes at all to the user-facing product.
Today, we have a Base class that contains all of the "shared" methods, which are not specific to any particular source. Then, each source has it's own class which inherits from the base. These data source classes are responsible for fetching the data, verifying the responses are valid, and providing standardized accessor methods that dig into the response bodies and normalize the data points.
To fetch the data, we use an excellent Ruby gem called Typhoeus which is "like a modern code version of the mythical beast with 100 serpent heads." Parallelizing our API requests allows us to provide quick responses from data sources that require multiple API hits to collect everything needed to power our UI. For example, the AccuWeather API requires 1 call to translate a latitude/longitude into a location ID, then 4 more calls to fetch the current conditions, hourly forecast, daily forecast, and alerts.
A simple sample
Here's a simplified example that illustrates some of the topics we've covered, omitting the sunset methods and AccuWeather's data method for brevity:
class Weather::Base
def timeout
if top_of_the_hour? || @context.fallback
4.seconds
else
2.seconds
end
end
def night_mode?
timezone.now < sunrise || timezone.now > sunset
end
private
def top_of_the_hour?
Time.now.min.zero?
end
end
class Weather::DarkSky < Weather::Base
def data
response = Typhoeus.get("https://api.darksky.net/...", timeout: timeout)
if response.timed_out?
@context.timeout = "ds"
raise TimeoutErr
end
if response.code == 200
JSON.parse(response.body)
else
raise DataError
end
end
def timezone
ActiveSupport::TimeZone[data.timezone]
end
def sunrise
timezone.at(data.daily.data.first.sunriseTime)
end
end
class Weather::AccuWeather < Weather::Base
def timezone
ActiveSupport::TimeZone[data.location.TimeZone.Name]
end
def sunrise
timezone.parse(daily_forecasts.first.Sun.Rise)
end
private
def daily_forecasts
data.daily.DailyForecasts.select do |time|
timezone.parse(time.Date).to_date >= timezone.today
end
end
end
Notice how the timezone and sunrise methods are specific to the API response from the data source. If we normalize those accessor methods, we can have a shared method on the base class called night_mode? which we use to determine if we should switch into our custom night mode styling. You can also see an example of the timeout / data error setup that we talked about earlier in the data method for Dark Sky.
An aside to thank our eagle-eyed customers
I picked the above example because of the AccuWeather daily_forecasts method, which has an interesting backstory. A few weeks ago, a customer reported an issue where the high/low for the first day in their daily forecast didn't match up with the hourly bar chart just above.
Typically when we encounter this kind of issue, we begin by asking the customer if they'll share their location and the data source they're using. With that information, we can reproduce the issue and capture the live data using VCR before we work up a fix. Ideally, we can move quickly enough to deploy and contact the customer to verify the fix before the issue disappears.
In this case, we found that AccuWeather was returning the previous day in the DailyForecasts array for a short while after midnight, where we expected the first day in DailyForecasts to always be today. This turned out to be an easy fix, and I think it's a great example of the importance of being able to deploy improvements quickly, as well a testament to our eagle-eyed customer base 🧐 — thank you!
Context and version syncing
Another thing you may have noticed in the above code sample is the context object. This is a place where we hold everything about the request that isn't related to the weather. For example, the options selected by the user and the version of the app making the request. The version is especially important because we need to keep our server-side code in sync with our native apps.
For example, you may remember our nailing the basics post where we talked about expanding our icon set. Some of our icons are served via our Cloudfront CDN, but some of them (for example, the widget and Apple Watch) are embedded in the native code. That means older versions of the app without the new icon assets need to continue using the old code.
Here's a partial example showing how we handled version syncing the icons:
class Context
def use_new_icons?
if ios?
version >= Gem::Version.new("3.2")
elsif android?
version >= Gem::Version.new("3.0.2")
end
end
end
class Weather::Base
def icon
if @context.use_new_icons?
icon_v2
else
icon_v1
end
end
end
class Weather::AccuWeather < Weather::Base
def icon_v1
case data.currently.WeatherIcon
when 19, 20, 21, 22, 23 then "snow"
end
end
def icon_v2
case data.currently.WeatherIcon
when 19 then "light-snow" # Flurries
when 20 then "light-snow" # Mostly Cloudy w/ Flurries
when 21 then "light-snow" # Partly Sunny w/ Flurries
when 22 then "snow" # Snow
when 23 then "snow" # Mostly Cloudy w/ Snow
end
end
end
Here you can see we added an icon for light-snow in v2 and we're using that for cases where the AccuWeather icon description uses the word flurries.
Fancy tricks
Picking another example from our nailing the basics post, let's take a look at the code that powers the "hourly summary" section which changes over the course of the day.
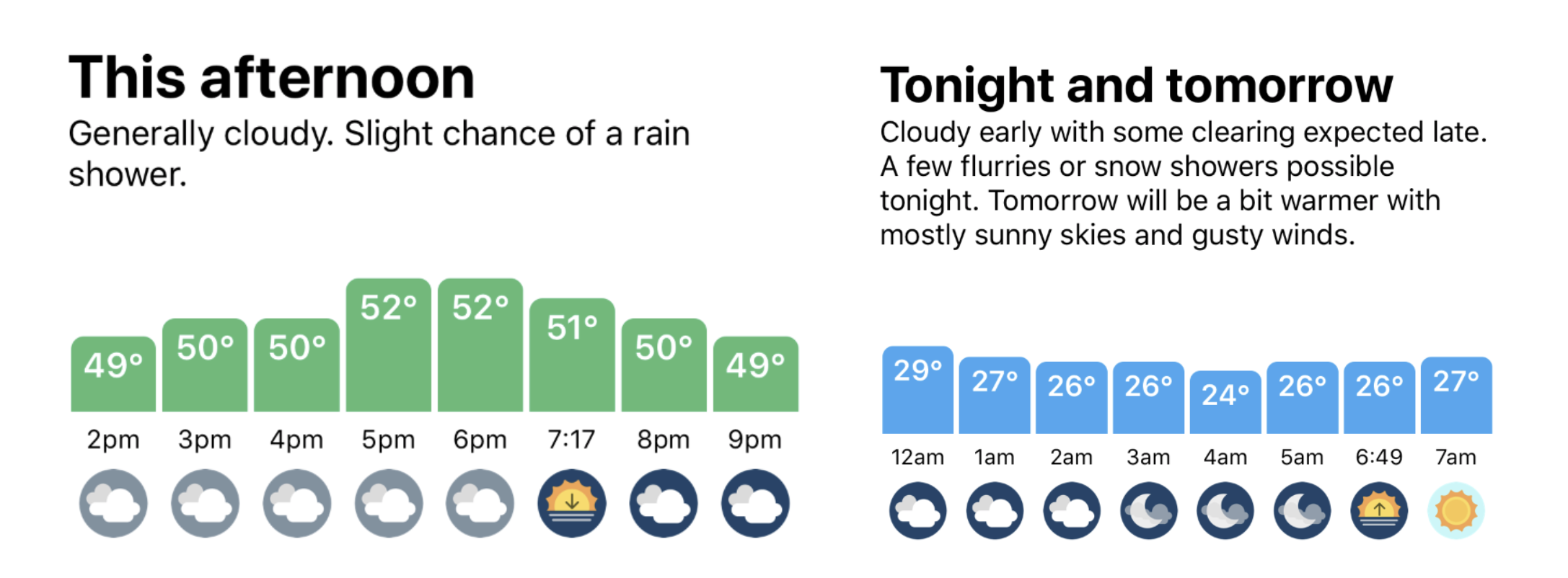
On the left you'll see an example of the view in the afternoon, and on the right you'll see a more complicated "tonight and tomorrow" example where we join two summaries and include some custom text generated based on the forecast data.
This section is mostly handled in the Base class since each data source class exposes the accessor methods needed to allow sharing the higher level logic. We'll simplify the code because I think this post is getting a bit long, but I'm sure you'll get the gist anyway:
class Weather::Base
def hourly_title
case time_of_day
when "morning" then "This morning"
when "afternoon" then "This afternoon"
when "evening" then "This evening"
when "night" then "Tonight and tomorrow"
end
end
def hourly_and_tomorrow_summary
if use_night_forecast?
"#{hourly_summary} tonight. #{tomorrow_summary}."
else
"#{hourly_summary}."
end
end
def hourly_summary
# ...provided by the data source class
end
def tomorrow_summary
# ...calculate the temperature change between today and tomorrow
# ...standardize the summary for tomorrow, making it suitable for use in a sentence
# ...attempt to generate a sensible string to join the temperature change and summary text
"Tomorrow will be #{temp_change} #{join_word} #{summary}"
end
private
def time_of_day
if use_night_forecast?
"night"
elsif timezone.now.hour.between?(0, 10)
"morning"
elsif timezone.now.hour.between?(11, 16)
"afternoon"
elsif timezone.now.hour.between?(17, 25)
"evening"
end
end
def use_night_forecast?
sunset_soon? || night_mode?
end
def sunset_soon?
timezone.now.between?(sunset - 2.hours, sunset)
end
end
One repo, one web app
Another interesting/novel thing we've done since first working together on Know Your Company is continuing to use a single repo to hold everything, and a single Rails app to power as much of the web side of things as possible. We even host our blog in the Rails app, using a quick and dirty Markdown processor.

We love the simplicity of this setup — fewer moving parts means less to manage. The basic idea is to isolate the controllers/layouts so we can have separate asset bundles etc. for each logical part of the app.
Here are simplified examples of our marketing, weather, and blog controllers:
class MarketingController < ApplicationController
layout "marketing"
end
class WeatherController < ApplicationController
layout "weather"
end
class BlogController < ApplicationController
layout "blog"
def show
@post = posts.detect { |post| post[:id] == params[:id] }
end
private
def posts
Dir["#{Rails.root}/blog/*"].map do |path|
{
id: File.basename(path, ".*"),
title: File.basename(path, ".*").gsub("-", " ").capitalize,
html: Redcarpet::Markdown.new(Redcarpet::Render::HTML).render(
File.read(path)
)
}
end
end
end
# app/views/layouts/blog.html.erb
<!DOCTYPE html>
<html>
<head>
<%= stylesheet_link_tag "blog" %>
<%= javascript_include_tag "blog" %>
</head>
<%=raw @post[:html] %>
</html>
While it's true that running something like WordPress would give us more features, our setup is dramatically simpler and most definitely "good enough" for our needs.
KISS, right?!
Enough!
So, I think that's about enough for today. I hope you enjoyed the tour.
If there's anything else you're curious about, please get in touch — we'd love to hear from you! ☺️